问题简述

如上图,拆分字段为多行,只使用MySQL本身功能,不借助其它工具。
下页结合实例详述原理,最后是完整的拆分语句。实际使用中,只需把最后一节的语句当作模板,修改字段名、表名即可。
核心知识点
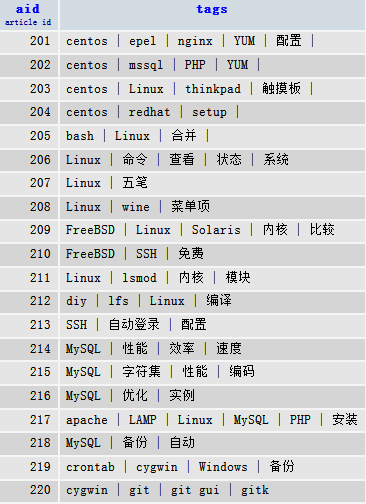
示例数据表article_tags
文章标签表,文章编号aid,及文章标签`tags` ;即待拆分tags数据,分隔符为 ” | “,竖线及前后空格共计三个字符。
CREATE TABLE `article_tags` ( `aid` int(11) NOT NULL COMMENT 'article id', `tags` varchar(255) NOT NULL DEFAULT '', KEY `aid` (`aid`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8;
辅助表sp_idx
拆分过程需要一张辅助表,包含了正整数的序列的一列数据。可按下页语句构造1024行。
CREATE TABLE `sp_idx` ( `id` smallint(5) unsigned NOT NULL AUTO_INCREMENT, `x` bit(1) NOT NULL DEFAULT b'0', PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='拆分辅助表(正整数序列)'; INSERT into `sp_idx`(`id`,`x`) values(1,0); INSERT into `sp_idx`(`x`) SELECT `x` FROM `sp_idx`; INSERT into `sp_idx`(`x`) SELECT `x` FROM `sp_idx`; INSERT into `sp_idx`(`x`) SELECT `x` FROM `sp_idx`; INSERT into `sp_idx`(`x`) SELECT `x` FROM `sp_idx`; INSERT into `sp_idx`(`x`) SELECT `x` FROM `sp_idx`; INSERT into `sp_idx`(`x`) SELECT `x` FROM `sp_idx`; INSERT into `sp_idx`(`x`) SELECT `x` FROM `sp_idx`; INSERT into `sp_idx`(`x`) SELECT `x` FROM `sp_idx`; INSERT into `sp_idx`(`x`) SELECT `x` FROM `sp_idx`; INSERT into `sp_idx`(`x`) SELECT `x` FROM `sp_idx`;
计算每条记录拆分条数
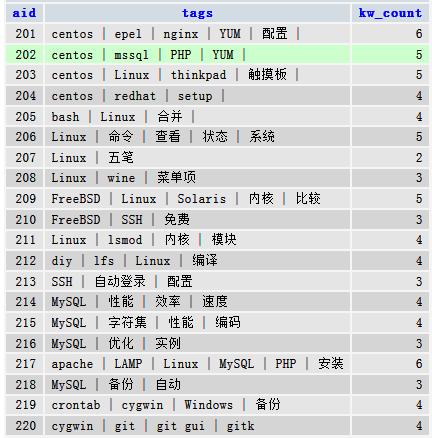
计算每行要拆分成的行数据,即有多少条数据通过分隔符拼接在一起。即计算字符串中删除分隔符后长度的减少量,即是 分隔符的个数*分隔符长度。分隔符个数+1 即是拆分条数。
这里使用char_length()计算长度;因为分隔符可能包含ASCII码,故不用length()。
SELECT r.`aid`, `tags`,
(char_length(`tags`)-char_length(REPLACE(`tags`,' | ',''))) DIV char_length(' | ') + 1 as kw_count
FROM `article_tags` r ;
联入入辅助表
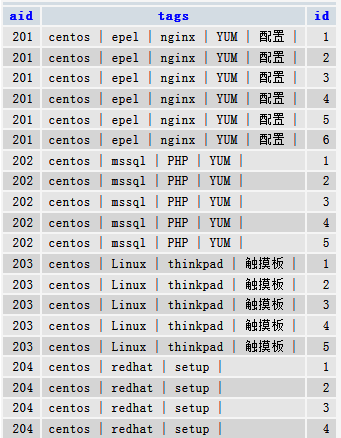
按上步计算出的kw_count,联入相应条数的序列数据,从1 到 kw_count,序列数据从辅助表取。联表关系使用 < ,而不是通常使用的等于。
SELECT r.`aid`, `tags`
,x.`id`
FROM `article_tags` r INNER JOIN `sp_idx` x
ON x.`id` <= (char_length(tags)-char_length(REPLACE(tags,' | ',''))) DIV char_length(' | ') + 1
;
按序号取子串
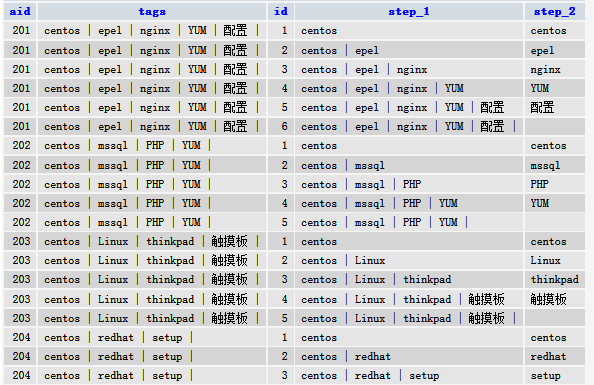
结果记录集最后一列id,事实上就是原始字符的排序号。每条记录按该序号截取子串即是结果了。这里使用 SUBSTRING_INDEX() 函数,截取前N段或后N段子串。
第一步,如下,截前N段子串的结果,再截最后一段即是每行所需结果。
SELECT r.`aid`, `tags`
,x.`id`, substring_index(`tags`,' | ',x.`id`) as step_1
,substring_index(substring_index(`tags`,' | ',x.`id`),' | ',-1) as step_2
FROM `article_tags` r
INNER JOIN `sp_idx` x
on x.`id` <= (char_length(tags)-char_length(REPLACE(tags,' | ',''))) DIV char_length(' | ') + 1
;
总结整个过程
SELECT r.`aid`, `tags`
,x.`id` as idx, substring_index(substring_index(`tags`,' | ',x.`id`),' | ',-1) as piece
FROM `article_tags` r INNER JOIN `sp_idx` x
ON x.`id` <= (char_length(`tags`)-char_length(REPLACE(`tags`,' | ',''))) DIV char_length(' | ') + 1
WHERE r.`tags`!='' HAVING `piece` !='';
该语句,可以当作模板使用,其中:
- `tags` 替换为待拆分字段(共4处),’ | ‘ 为分隔字符串(共4处);
- `piece`为拆分结果列,`idx` 为 `piece`在原始`tags`中的序号;
- 比前面步骤增加了WHERE及HAVING子句,用来排除原表tags为空字符串的行、及拆分piece为空字符串的行。
辅助表`sp_idx`需要事先建好,事实上只要从是从1开始的整数序列即可;如果待拆分子串数超过1024,则要扩充本表,多跑几次该句即可:INSERT into `sp_idx`(`x`) SELECT `x` FROM `sp_idx`;
如果实在不方便建辅助表,可以使用`mysql`. `help_topic`表的help_topic_id字段(不推荐)。要能保证其完整性,而且最大拆分子串数不大于`help_topic`的总行数。而且还要多加个where条件 help_topic_id>0,否则会拆分出多余的空串行,因为help_topic_id字段是从0开始编号的。
附件:
示例数据及SQL脚本 split_field_to_lines_in_mysql.zip
Last Updated on 2019/06/17