wordpress文件附件转移到另外服务器上实现性能提升/web与文件数据分离
在大型web架构里,通常会把web与文件分离在不同服务器上,以提升web系统的高效运行。
而wordpress,本身好像没有这方面的考虑,所以,但可以朝这方面努力,应该可以通过插件等机制实现。
以下是笔者刚想到的一个实现方案。
由于wordpress本身,添加文章后,其中引用文件都是以绝对链接[……]
这是fengyqf的博客
算是个Tag标记,针对常规的原创文章。仅对于 2012年以前的文章,为了区分于当时从其他网站上“转载”而来的内容,才使用这个分类。(2025/12/31)
在大型web架构里,通常会把web与文件分离在不同服务器上,以提升web系统的高效运行。
而wordpress,本身好像没有这方面的考虑,所以,但可以朝这方面努力,应该可以通过插件等机制实现。
以下是笔者刚想到的一个实现方案。
由于wordpress本身,添加文章后,其中引用文件都是以绝对链接[……]
今天真的载了,居然wordpress也被挂马了,太不可思议了。
事情如下:
晚上发篇文章,突然想到了一个对wordpress进行改进的方案,图片/附件与web分离,当然这个需求可能极少见,因为大多数wordpress都不会遇到这样的问题:空间不够用(直接升级主机了)、对附件的下载打开严重[……]
服务器特点:的相对性
dns解析,tcp/ip网络,必须有ip地址才能数据传输
http封包
osi七层协议
定义
主机:连接在网络上,有通过网络进行数据收发的设备。对于web开发而言,主要关心指web服务器,数据库服务器,普通用[……]
工作环境 Windows Server 2003 ,MySQL安装目录 D:\Program Files\MySQL\MySQL Server 5.0 , WinRAR 安装目录 C:\Program Files\WinRAR
备份数据存储的路径为 E:\dataBackup\MySQL .下面即[……]
背景:
普通笔记本电脑,新换了一只500G硬盘,安装操作系统时,基于把Linux/fedora作为首选OS的原因,规划分区如下
sda1 ext2 linux /boot 1G sda2 扩展分区 sda5 ext3 linux / 30G sda6 ntfs w[......]
小心雷区:网站结构更改时,对网页做301转向
真实案例://真实域名已隐去
1. 原域名show.my-domain.com 曾经使用301转向永久重定向到www.my-domain.com.cn ,但经alexa监测,www.my-domain.com.cn,的流量并没有增加,而show.[……]
fedora自带的yum更新源有时更新很慢,只有几K的下载速度,所以配置国内的yum更新源是很有必要的。
公网网络里使用163开源镜像是一个很好的选择,http://mirrors.163.com/ ,里面有很多个项目的yum源,而且在最右一栏里还配有说明文档,按其中如下部分操作
500G硬盘,规划分区如下(图从略),
sda1 ext2 linux /boot
sda2 扩展分区
sda5 ext3 linux /
sda6 ntfs windows安装分区
下略
使用linux格式化要安装windows的分区,格式化时要[……]
下载一个“Windows XP电脑维护工具箱”,点里面的“其他综合设置”,把“IE主页”一输入框清空(当然不清也可以,只是它会修改ie首页),其它的表单项不用改,再点下“执行”就可以了。
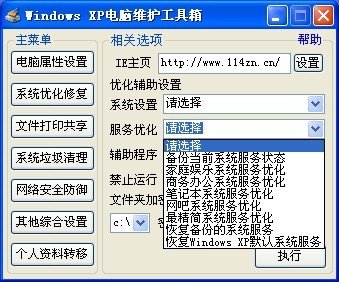
这是官方下载
http://www.sangsan.cn/article/soft/130.ht[……]
这里只讲firefox版,IE用户请绕行,如有兴趣请参看本站其它更多精彩文章。
alexa 工具栏是很多站长或有互联网技术背景人士的重要参考工具,但默认安装时它位于firefox的工具栏上,占据一行的高度,对于宽屏显示器而言,很是浪费空间,所以有必要只让它占据一个较小的位置。
不过写本文[……]